Not All VLMs Can Do OCR: A Case Study on Academic Paper Transcription
I needed to OCR academic papers with high fidelity. Not “get the gist” fidelity. Character-perfect fidelity, where (Gollwitzer & Bargh, 1996) stays exactly that and doesn’t become (Golliver & Bergh, 1996).
Vision Language Models seemed like the obvious tool. Multiple VLM architectures now run locally on Apple Silicon. But which model should I actually use?
I ran a single-page case study to find out. The results were dramatic enough to share, even before scaling to a full benchmark.
Setup
Test material: Page 3 of Higgins (1997), “Beyond Pleasure and Pain” — a vector PDF of an academic psychology paper with dense prose, numerous APA-style in-text citations, and section headings in a decorative font. About 6,300 characters of running text. No math formulas, tables, or figures on this page.
Runtime: Ollama v0.20.0 on a remote Mac Studio (M4 Max, 128GB RAM), accessed via SSH tunnel. Ollama uses GGUF inference, which may differ in speed and output from native MLX.
Models tested (Ollama tags and digests as run):
| Model | Ollama tag | Digest | Quantization | Reported params |
|---|---|---|---|---|
| GLM-OCR | glm-ocr:latest | 6effedd0 | F16 | 1.1B (official: 0.9B) |
| Qwen2.5-VL | qwen2.5vl:latest | 5ced39df | Q4_K_M | 8.3B |
| Gemma 4 | gemma4:latest | c6eb396d | Q4_K_M | 8.0B (E4B: 4.5B effective) |
| Gemma 3 | gemma3:4b | a2af6cc3 | Q4_K_M | 4.3B |
| Qwen3-VL | qwen3-vl:4b | 1343d82e | — | — |
| MiniCPM-V | minicpm-v:latest | c92bfad0 | — | — |
Prompt: "OCR the text in this image. Output the exact text as it appears." Same prompt for all models. No model-specific prompt tuning was attempted.
Parameters: Temperature 0.1, no streaming, 600-second timeout. Input images rendered at 200 DPI via PyMuPDF. Single run per model, no warm-up.
Baseline: GLM-OCR, a VLM by Zhipu AI specifically trained for OCR (CogViT visual encoder + GLM-0.5B language decoder). I also compared against PDFKit text extraction as a non-OCR reference (reads embedded text directly from vector PDFs, zero cost).
Metric: Word-level agreement ratio computed via Python difflib.SequenceMatcher after whitespace normalization, measured against GLM-OCR output. This is not a standard OCR metric (CER/WER). It measures agreement with the baseline, not absolute correctness — addressed in the verification section below.
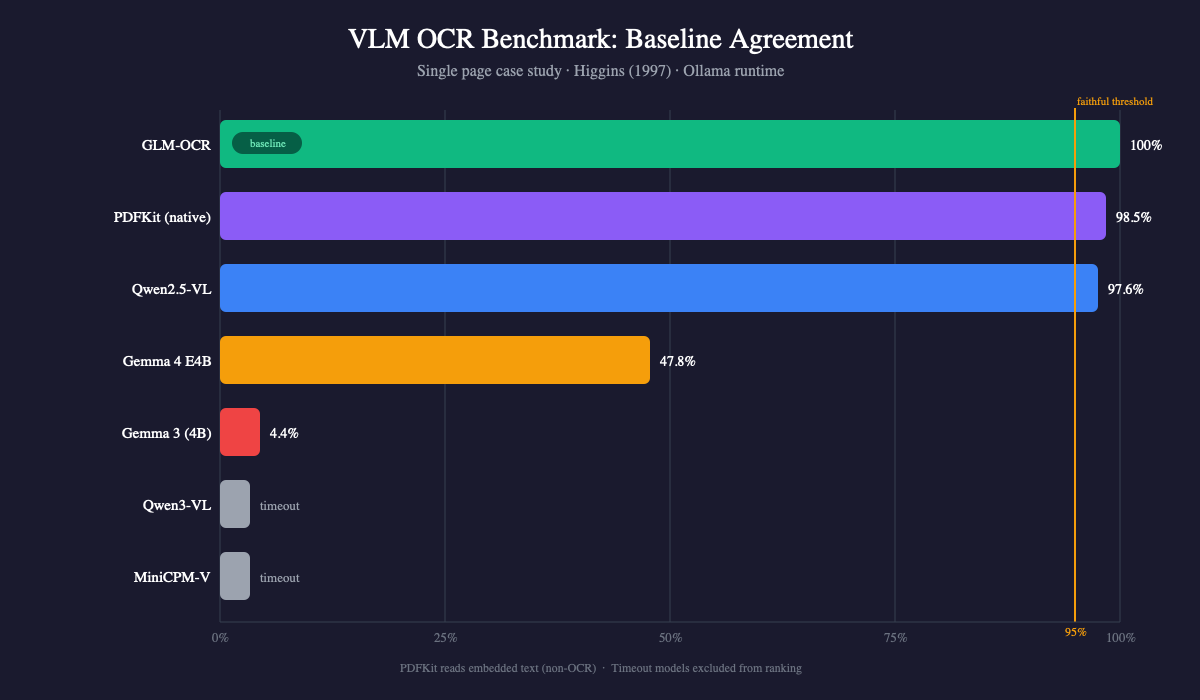
Results
| Rank | Model | Output Length | Wall-clock (single run) | Baseline Agreement |
|---|---|---|---|---|
| 1 | GLM-OCR | 6,314 chars | 21.5s | baseline |
| 2 | Qwen2.5-VL | 6,313 chars | 35.9s | 97.6% |
| 3 | Gemma 4 E4B | 4,346 chars | 23.4s | 47.8% |
| 4 | Gemma 3 (4B) | 3,272 chars | 8.6s | 4.4% |
| — | Qwen3-VL (4B) | — | >600s (timeout) | — |
| — | MiniCPM-V | — | >600s (timeout) | — |
Non-OCR reference: PDFKit extracted 6,311 chars with 98.5% word agreement to GLM-OCR. PDFKit reads embedded text, not images, so it’s a different task — included for cross-validation, not as a competing OCR method.
The two models that timed out may have been affected by cold start (first model load in Ollama). I did not re-run them, so their timeout should not be taken as definitive evidence of inference speed.
GLM-OCR: The Baseline
On this test page, GLM-OCR produced what appeared to be a highly faithful transcription. On the adjudicated differences and spot-checked passages, every citation matched the source image:
(Carver & Scheier, 1981, 1990; Gollwitzer & Bargh, 1996;
G. A. Miller, Galanter, & Pribram, 1960; Pervin, 1989;
von Bertalanffy, 1968)It preserved typographic details: en-dashes for compound adjectives (approach–avoidance), curly quotes, proper apostrophes. 6,314 characters, closely matching the page content.
Qwen2.5-VL: Strong Runner-Up
97.6% word agreement with GLM-OCR. Character count nearly identical (6,313 vs 6,314). The differences were cosmetic: straight quotes where GLM-OCR used curly quotes, hyphens where GLM-OCR used en-dashes.
I did not observe content errors, hallucinations, or missing text on this page, though without a full human transcription this cannot be stated definitively.
Gemma 4: Google’s Latest, and It Doesn’t Help
Gemma 4 is Google’s newest multimodal model family (2026). I tested the E4B variant (4.5B effective parameters, 8B with embeddings) via Ollama’s gemma4:latest. It seemed like it should handle OCR well. On this page, it didn’t transcribe — it rewrote:
Original: “what exactly does this entail?” Gemma 4: “what exactly does suit?”
Original: “Thorndike (1911) did in his law of effect” Gemma 4: “Thorndike did (1911) did in law of fit”
Every citation it touched was wrong. Gollwitzer became Golliver. Bargh became Bergh. Pribram became Pribran. Pervin became Ferris. von Bertalanffy became Verlan.
It also dropped 27% of the content (4,346 chars vs 6,314). A 0.9B OCR-specialized model outperformed Google’s latest general-purpose VLM by a wide margin on this task. Newer and bigger doesn’t mean better when the task is faithful transcription.
Gemma 3: Pure Hallucination
4.4% agreement. Where the original discussed Thorndike’s law of effect, Gemma 3 generated sentences about “a legal doctrine that would be applied” and “a student became ill, the study was postponed.” Fabricated text that happened to be about psychology.
Why Such a Gap?
On this page, models fell into two behavioral categories:
| Behavior | Models | Result on This Page |
|---|---|---|
| Transcribe what’s in the image | GLM-OCR, Qwen2.5-VL | Faithful output |
| Understand the image, then generate a response | Gemma 3, Gemma 4 | Paraphrased or hallucinated |
The interesting case is Qwen2.5-VL: it’s a general-purpose VLM, not OCR-specialized, yet it transcribed faithfully. So the failure mode isn’t simply “general-purpose = bad at OCR.” It’s more specific: under this prompt and runtime, Gemma 3 and Gemma 4 defaulted to a generative mode that paraphrased rather than transcribed.
A framework from cognitive psychology helps describe what’s happening. Human perception involves bottom-up processing (data-driven, building percepts from raw sensory input) and top-down processing (knowledge-driven, using expectations and context to interpret input). These aren’t two separate modes — they interact constantly. But the balance between them matters for the task at hand.
flowchart LR
subgraph BU["Dominant: bottom-up"]
direction LR
I1["Page image"] --> V1["Visual features"] --> C1["Characters"] --> T1["Faithful text"]
end
subgraph TD["Dominant: top-down"]
direction LR
I2["Page image"] --> V2["Visual features"] --> S2["Semantic understanding"] --> G2["Generated response"]
S2 -.->|"language prior\noverrides visual"| G2
end
style BU fill:#1a3a2a,stroke:#10B981,color:#fff
style TD fill:#3a1a1a,stroke:#EF4444,color:#fff
style T1 fill:#10B981,stroke:#10B981,color:#fff
style G2 fill:#EF4444,stroke:#EF4444,color:#fffThis diagram describes the dominant behavior observed in this test, not the models’ internal architecture.
Faithful OCR requires prioritizing visual evidence over semantic plausibility. But more capable general-purpose VLMs appear to have stronger top-down tendencies: they “understand” the text and generate what they expect should be there, rather than what is there. Gemma 4 turning “law of effect” into “law of fit” looks like a case where the model’s language prior overrode the visual evidence — though other explanations (training data, instruction tuning, decoding strategy) cannot be ruled out from this data alone.
GLM-OCR, trained specifically for OCR, behaved more like a bottom-up-dominant system on this page: it mapped visual features to characters without trying to comprehend or improve the content.
Why Qwen2.5-VL avoided the top-down trap while Gemma didn’t, I can’t say from one page. Possible factors include training data mix, instruction tuning approach, or how each model balances visual fidelity against semantic generation. I did not attempt model-specific prompt engineering (e.g., “transcribe verbatim, do not paraphrase”). It’s possible that more targeted prompts could shift Gemma’s balance, though the scale of hallucination in Gemma 3 (4.4% agreement) suggests the issue may run deeper than prompting.
Adjudicating Mismatches
The agreement scores above measure model-to-model consistency, not absolute correctness. To verify, I had Claude Opus 4.6 examine the original page image alongside all outputs, adjudicating each difference against the source.
The 23 differences between PDFKit and GLM-OCR fell into five categories:
| Difference | PDFKit | GLM-OCR | Verdict |
|---|---|---|---|
| Heading glyph corruption | Re.gu!a.tory | Regulatory | GLM-OCR matches image |
| Missing hyphens | selfregulation | self-regulation | GLM-OCR matches image |
| Dash type | hyphen (-) | en-dash (–) | GLM-OCR matches typeset |
| Quote style | straight | curly | GLM-OCR matches typeset |
| Apostrophe style | straight | curly | GLM-OCR matches typeset |
These differences were all clear-cut (garbled text vs readable text, or ASCII vs. correct Unicode). GLM-OCR matched the source image on all 23 adjudicated points.
For body text where GLM-OCR and PDFKit agreed, I spot-checked the most error-prone elements: long citation strings with unusual author names (von Bertalanffy, Cooley, 1902/1964). These matched the source image.
Two independent extraction methods (PDFKit reading embedded text, GLM-OCR reading the rendered image) agreeing on content is evidence of correctness — though not proof. A full human transcription would be needed for definitive ground truth.
Limitations
This is a single-page case study, not a comprehensive benchmark:
- One page, one paper, one PDF type. A vector PDF with English prose. Results may differ on scanned PDFs, math-heavy papers, tables, figures, multi-column layouts, or non-Latin scripts.
- No prompt tuning. The same generic prompt was used for all models. Model-specific prompting could change results, especially for general-purpose VLMs.
- Ollama runtime only. Models ran through Ollama’s GGUF inference, not native MLX. Speed and output quality may differ on other runtimes.
- Single run per model. No repeated trials or variance reporting. OCR outputs at low temperature should be mostly deterministic, but this was not verified.
- No standard OCR metrics. I used word-level
SequenceMatchersimilarity rather than CER (Character Error Rate) or WER (Word Error Rate), which are standard in OCR evaluation. - No independent ground truth. Scores measure agreement with GLM-OCR, not accuracy against a human transcription. This may systematically favor the baseline. Without full human ground truth, the agreement percentages should not be read as accuracy.
Takeaway
On this page, with this prompt and runtime:
GLM-OCR alone was the best option. A 0.9B model purpose-built for OCR outperformed every larger general-purpose model. It transcribed faithfully, got citations right, and preserved typography. If you only run one model, this is the one.
Qwen2.5-VL was the surprise. At 97.6% agreement with only cosmetic differences, it performed far better than Gemma 3 (4.4%) and Gemma 4 (47.8%), despite all three being general-purpose VLMs. This means the failure mode isn’t “general-purpose models can’t do OCR.” Some can. But you can’t assume a general-purpose VLM will transcribe faithfully just because it’s large or new. On this page, Google’s latest Gemma 4 hallucinated citations while a smaller Qwen model got them right.
The broader point: this result pushes back against the assumption that the most capable general-purpose model will always perform best. Google’s Gemma 4, a model designed to understand images, audio, and chain-of-thought reasoning, hallucinated author names that a 0.9B specialist got right every time. More intelligence doesn’t mean better performance on every task. Sometimes it means more ways to get things wrong.
This mirrors what we know about human expertise. A domain expert doesn’t outperform a novice by being “smarter” across the board. They outperform by having task-specific representations — a radiologist relies on rapid perceptual recognition of visual patterns, complemented by but not reducible to anatomical reasoning. Similarly, GLM-OCR maps visual features to characters through a direct path, while Gemma routes through semantic comprehension and back out. For OCR, the specialist’s more direct path was the more reliable one.
Speculative Note
One way to read this result: scaling up a model may involve trade-offs, not just gains. As models acquire higher-order capabilities (reasoning, summarization, instruction following), their dominant processing mode may shift away from the kind of low-level perceptual fidelity that tasks like verbatim transcription require.
There’s an evolutionary analogy worth considering, though imperfect. Humans developed abstract reasoning and language, but comparative studies suggest we may have traded off some capacities that other primates retain. In certain rapid spatial memory tasks, trained chimpanzees have outperformed human participants — though the extent and interpretation of this advantage remains debated. The point isn’t that chimps are “better” or that humans “lost” a capability in any simple sense. It’s that cognitive specialization involves rebalancing, not just stacking.
If something similar applies to VLM scaling, the trend toward ever-larger general-purpose models won’t make specialized models obsolete. It may make them more necessary, for exactly the tasks where general intelligence gets in the way. This is speculation from a single-page case study, not a conclusion — but it’s a pattern worth watching.
Benchmark code: Tests/OCRTests/benchmark_ocr.py